
About the Artist2 NoE
- Strategic Objectives
- Approach
- Joint Programme of Activities (JPA)
- Artist2 Core Partners
- Research and Integration
- Workshops
- Education
- International Collaboration
- State of the Art
- Related Projects
- Conclusions from the Final Review

Research and Integration Activities for the "Excution Platforms" cluster
Design for Low Power
JPRA-Cluster Integration
Activity Leaders: Petru Eles (Linkoping University) Artist2 Clusters: | Contents |
 Abstract
AbstractPower dissipation has become one of the most serious obstacles in the evolution of electronic systems. Historically, the transition from one CMOS technology generation to the next has been accompanied by a jump in power density, as well as increased active-state and stand-by power consumption. Furthermore, mainstream architectural design is moving towards energy-hungry programmable/configurable architecture meeting ever-increasing performance requirements. It is the objective of this activity to develop, promote and integrate methods that address power and energy issues across several layers of abstraction.
Baseline
The group of Luca Benini at the University of Bologna (UoB) is one of the leading centers in low power design, focusing on system level power management both from the architectural and from the software viewpoint. In this area, the group has produced a large number of contributions on OS-Based-dynamic power management, memory and communication architecture optimization for low power consumption, low power circuit design, battery-driven power management.The group of Jan Madsen at the Technical University of Denmark (DTU) aims at low-power techniques for wireless sensor networks, and it brings significant experience on low-power asynchronous circuit design, as well as analytic and stochastic modeling of power consumption and battery usage. They have developed exploration methods for mapping applications onto heterogeneous multiprocessor platforms based on a multi-objective optimization framework from ETH Zurich, where one of the objectives is power consumption.
The group of Petru Eles at Linkoeping University (LIU) has given important contributions on high-level system modeling of both power and reliability, and on optimization techniques for energy efficient mapping of applications on execution platforms. They have developed approaches for energy efficient implementation of both hard and soft real-time systems.
The group of Lothar Thiele at ETH Zurich (ETHZ) has a long standing experience in the area of sensor networks. In particular, a low power platform including hardware, operating system, middleware and various applications has been developed (BTnode). It is used by many research groups worldwide. Together with the experience in real-time systems and scheduling, this is the basis for the joint effort in the design of low power massively distributed systems.
Previous Work
Work performed in months 1-6Bologna University has worked on interconnect optimization techniques for low power. Several schemes have been developed to instantiate application (platform) specific interconnect architectures for minimum energy consumption. An algorithm for automatic instantiation of multi-hop busses which includes topology generation and bus frequency assignment has been developed in collaboration with Penn State University. Additionally several extensions to the power modeling infrastructure in the MPARM virtual platform simulators have been developed, including the model for variable frequency and variable voltage cores, as well as a prototype model for estimating the power consumption of IOs and external memories (this work has been performed in cooperation with associate partner STMicroelectronics).
Linkoeping University has developed a technique for static routing on NoC, with guaranteed delays and arrival probabilities in the presence of transient faults. The approach is based on schedulability analysis of tasks and messages with priority based arbitration. For fault-tolerance, a combination of spatial and temporal redundancy is considered. Reduced communication energy is one of the goals. More recently the analysis of the worst-case buffer space needed has been performed. Based on this analysis, it is possible to develop an approach to buffer space minimization in the context described above.
Technical University of Denmark has started the development of a generic sensor network platform (Hogthrob project) which allows to tradeoff hardware and software implementations of the various components of the platform. So far, the focus has been on: (1) Processor design: Low-power design techniques have been investigated, included low-power synthesis (e.g., clock-gating), power modes and de-synchronizing in the context of the OpenCores AVR core (2) Power modeling: Simulation-based power modeling and estimation techniques have been investigated. This involves analytic and stochastic modeling of batteries and investigation into the macromodeling of various hardware components.
Work Performed in Months 7-12
Bologna University has started a research effort on energy aware mapping of multi-task applications on multi-processor SoC execution platforms. The approach is based on variable-voltage processors where execution speed and voltage supply can be independently adapted to the processor’s workload. The first result of this effort has been a design space exploration technique that automatically finds Pareto points in the power vs. throughput design space. The technique has been tested on streaming-like signal processing applications.
Linkoeping University’s most recent efforts are aiming at a more accurate modeling of actual communication and memory techniques used in MP SoC. Such an accurate modeling is needed in order for a system level analysis and optimization to produce useful results. Thus, work is concentrating on: (1) Capturing the background communication due to cache misses in system level models. (2) Capturing the bus load due to system-wide synchronization. Once these modeling issues are solved, different optimization techniques can be used for e.g. task mapping and scheduling, as well as voltage selection. Results can be validated using accurate and fast simulation in the environment developed at Bologna. Another issue which has been tackled is that of efficient optimization techniques based on advanced constraint solving and mathematical programming techniques. This work has been performed in cooperation with the group at University of Bologna.
In the framework of the research on low power wireless sensor networks (Hogthrob Project), the focus of the Technical University of Denmark has been on: (1) Processor design: DTU is currently investigating architectures for bit compression and bit-serial computation in the context of the BitSNAP core. (2) Power modeling: development of a sensor network power model within the UppAal model checking environment which allows for a formal analysis of power consumption within the network. (3) Empirical power estimation: Based on the prototype sensor network platform developed within Hogthrob, various testbench programs have been run on an AVR core synthesized on the FPGA and a number of physical measurements have been conducted. Finally, DTU has initiated the investigation on how the power modeling and the sensor network modeling can be captured within the multiprocessor simulation environment, ARTS, developed at DTU.
Problem Tackled in Year2
The high-level objective of the activity is the investigation of a comprehensive hardware-software power analysis and optimization approach for single and multi-processor embedded systems.More specifically, in Year2 several relevant issues in this domain have been tackled:
- Power modeling for complex SoC platforms. The main objective here is to develop power models that provide a high-level view of the power consumed by a complex SoC platform to both the hardware architect and the software developer. In this area, the most critical challenge is to provide reasonably accurate power and energy consumption information at the high level of abstraction typically adopted during architecture and software design. In Year1 the basic elements for a system-level power estimation framework have been integrated. In Year2, the focus has been on modeling system components at different level of abstraction and on improving the generality of the power modeling framework to support more complex platforms with multi-hop interconnects and multiple frequency and power domains.
- Power optimization via system-level resource allocation and scheduling. The main objective here is to develop techniques for optimally mapping multi-task (parallel) applications onto System-on-chip (SoC) platforms with multiple processors (MP-SoCs). This is an industry-relevant problem, as most high-end embedded computing platforms in a number of target markets (automotive, multimedia, networking) are evolving toward multi-core architectures. The most critical challenge in this area is the complexity of the problem of optimally mapping tasks onto cores (and storage resources), while selecting frequency and voltage assignments for the various cores. The focus in Year2 has been on a “static allocation” approach that assumes the knowledge of application workload requirements. The issue of both hard and soft real-time systems has been addressed.
- Scheduling based energy optimization for energy-scavenging wireless sensor networks. Sensor networks are an increasingly important class of distributed embedded systems. Wireless sensor networks are strategic enablers for a number of “ambient intelligence” applications, such as environmental monitoring, monitoring of body functions, tracking of people and objects. The main objective tackled here is the development of novel techniques for scheduling activities on sensor network nodes depending on the availability of environmental energy. The end goal is to enable sustainable environmentally powered operation for sensor networks. In year two, the main focus has been on the new class of energy-harvesting devices. In this case, the available energy is replenished, e.g. by the use of solar cells or other harvesting devices. In year 2, we have been investigating the (optimal) task scheduling problem under the energy-harvesting model. Here, the expertise of the research groups in Bologna and ETH Zurich has been combined towards the first result in this quickly growing area.
Current Results
Power modeling for complex SoC platformsThe activity has focused on extending system-level energy analysis to highly integrated MPSoC platforms with segmented bus architectures, where the efficiency of bridges and protocol/frequency/size converters comes into play to determine the performance of the system interconnect. We leveraged a close cooperation with associate member STMicroelectronics which provided the models, traffic generators, system specifications and performance requirements. Platforms based on the on-chip communication protocols STBus, AMBA AHB, AMBA AXI-have been modeled and simulated at a very high level of accuracy (cycle-accuracy and bus-signal-accuracy), and compared with mixed AHB/AXI platforms.
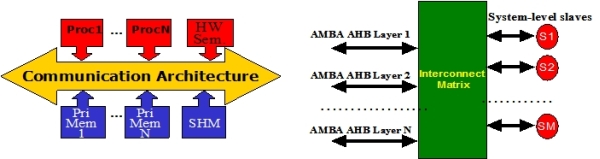
Fig 1 (a) Baseline single-node shared bus platform (b) advanced multi-layer interconnects
The original MPARM platform allowed the modeling and simulation of single-node communication architectures (as depicted in Fig.1a). The platform was enhanced with the possibility to extend the modeling capability to a multi-layer architecture, as illustrated in Fig.1b. The first scenario corresponds to low-end real-life platforms, where AMBA AHB, AMBA AXI or STBus are the architectures of choice to accommodate on-chip communication. The MPARM platform can also instantiate a NoC as the communication fabric, by wrapping the masters and slaves with the proper network interfaces. In general, all cores can be wrapped with the native bus interface. More complex MPSoC platforms adopt the communication architecture depicted in Fig.1b. It is a hierarchical infrastructure, where communication takes place at a first level of the hierarchy in the local AMBA AHB layers, and at a second level with the system-level slaves. The AMBA Multi-Layer specification introduced the notion of the interconnect matrix first, by envisioning point-arbitration at the destination slaves. This solution is quite interesting, since it allows a larger scalability than single-node solutions. Unfortunately, fabrication problems arise when the number of input layers increases a lot, since the implementation of the interconnect matrix is mostly combinational. This gives rise to clock frequency limitations and to layout unpredictability. As the level of integration of MPSoCs increases, the illustrated structures cannot satisfy communication requirements any more.
A further increase in communication scalability is exposed by segmented architectures, where a number of busses are interconnected with each other by means of bridges. In this case, the congestion on each bus is greatly decreased, thus favoring lower bus access times, but the latency of bus transactions can be seriously increased because of the multiple steps needed to reach a slave located on a different bus. Bridge traversal latency can significantly contribute to overall communication latency. Similarly, the use of bridges raises power concerns. The use of bridges helps to relieve the scalability limitations of traditional communication architectures, however the associated cost consists of the design of a complex IP block (the bridge itself) which is far from trivial and which can significantly affect system performance and energy. Many times, bridges do not perform only protocol conversion, but also size and frequency conversion. In fact, cores with homogeneous characteristics (i.e., clock frequency, data and address bus width) are typically grouped in the same node, therefore each “segment” of the global communication architecture turns out to be a domain with distinctive features. This obviously increases the bridging cost, since up/down size conversions or frequency conversions all take clock cycles to be carried out.
Another issue concerned the porting of traffic generators in order to make the simulation of complex systems in reasonable time possible. Moreover, this allowed overcoming confidentiality problems related to the intellectual property of communicating actors. STMicroelectronics made available its traffic generators for audio and video IP blocks, allowing us to reproduce on the MPSIM environment the traffic patterns of real-life set-top-box platforms with a high level of accuracy.
Another effect of the joint work on traffic generators between Technical university of Denmark and University of Bologna was the development of the necessary infra-structure to co-simulate modules of the abstract system-level MPSoC ARTS frameworks (DTU) with modules available in the cycle-true MPARM framework. The motivation of the work is to investigate MPSoC instances at mixed-levels of abstraction. A simple system where two ARTS IP cores were connected through a MPARM AMBA-AHB bus was successfully implemented and co-simulated.
Finally, a significant modeling effort was required also for the memory controller. In fact, MPSIM has traditionally simulated MPSoC systems with on-chip memories only; therefore we needed to model real-life memory controllers for I/O. We got the LMI specification from STMicroelectronics, and developed a SystemC model which was accurately (cycle-by-cycle) validated against the behavior of the real LMI. Such powerful model allows us to interface our MPSoC with SDR and DDR SDRAMs, and more interestingly to model I/O access latency of real systems. Finally, we retain the capability to model an on-chip shared memory in place of the off-chip SDRAM, thus being able to differentiate system performance and power in presence of a slow off-chip memory vs. a fast on-chip memory. Optimizations for access to the off-chip memory can also be analyzed with this platform.
The outcomes of this activity are: the development of a virtual platform for power modeling of complex multi-core systems on chip. This platform will facilitate further integration among partners and associates, thanks to is flexibility and generality.
Power optimization via system-level resource allocation and scheduling
In this activity, the focus is on addressing resource allocation problems in Multi-Processor Systems-on-Chip (MPSoCs). An important instance of this problem is when have to allocate and schedule a given task graph (representing a functional abstraction of a multi-task application) on a target multi core platform while choosing the frequency (and voltage) at which each task will be executed. Since hardware platforms and applications are extremely complex, it becomes thus important not only to measure the optimizer efficiency as done in general in the optimization area, but also to verify if the optimization model is accurate through a validation step performed via simulation on a virtual platform.
Allocation, scheduling and discrete voltage selection problem for variable voltage/ frequency MPSoCs, minimizing the system energy dissipation and the overhead for frequency switching, are clearly NP-hard problems. Only incomplete approaches have been proposed to solve these problems in the system design community. In this activity we have investigated a hybrid methodology based both on Constraint Programming (CP) and Integer Programming (IP) that splits the overall problem in two subproblems, the first being the allocation of tasks to processors and frequencies to tasks and the second being the scheduling. Our methodology derives static allocation, scheduling and frequency setting; therefore it targets applications with design-time predictable behavior.
In order to solve the problem to optimality without incurring accuracy limitations, we applied the concept behind the logic-based Benders decomposition technique to this new application problem. Bender decomposition can be summarized as follows. A complex optimization problem is decomposed in two parts: the first, called Master Problem, is the allocation of processors and frequencies to tasks and the second, called Subproblem, is the scheduling of tasks given the static allocation and frequency assignments provided by the master. The master problem is tackled by an Integer Programming solver while the subproblem through a Constraint Programming solver. The two solvers interact via generation of no-goods (constraints on acceptable solutions for the CP solver) and cutting planes (constraints on acceptable values of the integer variables for the IP solver) generation. The solution of the master is passed to the subproblem in an iterative procedure that is proved to converge to the optimal solution.
The methodology has been tested on a variety of realistic instances. In addition, we test the accuracy of the solutions provided by the optimizer simulating them on an MPSoC virtual platform. In particular, we have used two demonstrators (GSM and JPEG) to prove the applicability of the developed methodology to real-life embedded applications scenarios.
In a parallel, but strongly related activity, we have also addressed the specific problems of soft real-time systems. In this case, certain tasks are allowed to miss their deadlines. This however, negatively affects the delivered QoS. The goal is to maximize the QoS with a limited energy budget or to achieve a certain level of QoS with as low energy consumption as possible. We have developed heuristics which determine the system schedule and voltage levels of tasks in such a system.
Finally, DTU has experimented with the use of meta-heuristics to solve the mapping a set of task graphs onto a heterogeneous multiprocessor platform. The objective is to meet all real-time deadlines subject to minimizing system cost and power consumption, while staying within bounds on local memory sizes and interface buffer sizes. Our approach allows for mapping onto a fixed platform or onto a flexible platform where architectural changes are explored during the mapping. The approach uses multi-objective evolutionary algorithms and is based on the PISA framework for multi-objective optimization developed at ETH Zurich. We demonstrate the approach through an exploration of a smart phone, where five task graphs with a total of 530 tasks after hyper period extension are mapped onto a multiprocessor platform. The results show four non-inferior solutions out of 10.000 explored solutions, which tradeoffs the various objectives.
The outcome of this activity is the development of a methodology for design-time allocation, scheduling, frequency and voltage setting for multi-task applications onto MPSoC platforms. This outcome is a starting point for follow-up integration activities aiming at the extension of the methodology to more dynamic problems, where run-time decisions will be required
Scheduling based energy optimization for energy-scavenging wireless sensor networks
Wireless sensor networks – consisting of numerous tiny sensors that are unobtrusively embedded in their environment – have been the subject of intensive research. As for many other battery-operated embedded systems, a sensor’s operating time is a crucial design parameter. As electronic systems continue to shrink, however, less energy is storable on-board. Research continues to develop higher energy-density batteries and supercapacitors, but the amount of energy available still severely limits the system’s lifespan. As a result, size and weight of most existing sensor nodes are largely dominated by their batteries.
On the other hand, one of the main advantages of wireless sensor networks is their independence of pre-established infrastructure. That is, in most common scenarios, recharging or replacing nodes’ batteries is not practical due to (a) inaccessibility and/or (b) sheer number of the sensor nodes. In order for sensor networks to become a ubiquitous part of our environment, alternative power sources should be employed. Therefore, environmental energy harvesting is deemed a promising approach: If nodes are equipped with energy transducers like e.g. solar cells, the generated energy may increase the autonomy of the nodes significantly. Several technologies have been discussed how, e.g., solar, thermal, kinetic or vibrational energy may be extracted from a node’s physical environment. Moreover, several prototypes have been presented which demonstrate both feasibility and usefulness of sensors nodes which are powered by solar or vibrational energy.
The focus of this activity is on sensor nodes with energy-scavenging features. In general our results apply for all kind of energy harvesting systems which must schedule processes under deadline constraints. For these systems, new scheduling disciplines must be tailored to the energy-driven nature of the problem. This insight originates from the fact, that energy – contrary to the computation resource "time" – is storable. As a consequence, every time we withdraw energy from the battery to execute a task, we change the state of our scheduling system. That is, after having scheduled a first task the next task will encounter a lower energy level in the system which in turn will affect its own execution. This is not the case in conventional real-time scheduling where time just elapses either used or unused.
The main developments obtained in this activity can be summarized as follows
- We studied an energy-driven scheduling scenario for a system whose energy storage is recharged by an environmental source. For this scenario, we developed an optimal online algorithm that dynamically assigns power to arriving tasks. These algorithms are “energy-clairvoyant”, i.e., scheduling decisions are driven by the knowledge of the future incoming energy.
- We developed an admittance test that decides, whether a set of tasks can be scheduled with the energy produced by the harvesting unit, taking into account both energy and time constraints. For this purpose, we introduced the concept of energy variability characterization curves (EVCC).
- In addition, a comparison to earliest-deadline first (EDF) by means of simulation, demonstrated that significant capacity savings can be achieved by our approach, when compared to the classical EDF algorithm.
The outcome of this work is a novel scheduling strategy (called lazy scheduling) that is well suited to energy-harvesting systems operating under real-time constraints. It is the first result of this kind in this quickly growing research area and received a lot of attention in the scientific community. Two joint publications have been written.
Keynotes, Workshops, Tutorials
Invited Presentation: Luca Benini - Application Specific NoC DesignDesign Automation & Test in Europe Conference & Exhibition
Munich, Germany – 06-10 March, 2006.
See it online!!
Keynote: Luca Benini - NoCs: Vision, Reality, Trends
Special Workshop: on Future Inteconnects and Networks on Chip
Munich, Germany – 10 March, 2006.
See it online!!
Tutorial: Luca Benini – Dynamic Power Management
SBCCI: Symposium on Integratedi Circuits and Systems Design
Florianopolis, Brazil – 5 September 2005.
Tutorial: Lothar Thiele – Sensor Networks
Design Automation & Test in Europe Conference & Exhibition
Munich, Germany – 06-10 March, 2006.
See it online!!
Invited Presentation: Tobias Bjerregaard – Modular SoC-Design using the MANGO clockless NoC
International Conference on Parallel Computing (PARCO’05)
Malaga, Spain – 13-16 September, 2005.
See it online!!
Workshop : Artist2 Cluster meeting
Bologna, 22-23 May, 2006.
See it online!!
Publications Resulting from these Achievements
Power modelling for complex SoC platformsPower optimization via system-level resource allocation and scheduling
Scheduling based energy optimization for energy-scavenging wireless sensor networks
ARTIST2 Participants: Expertise and Roles
- Team Leader: Luca Benini - University of Bologna (Italy)
 (i) development of power modeling and estimation framework for systems-on-chip. (ii) Development of optimal allocation and scheduling techniques for energy-efficient mapping of multi-task applications onto multi-processor systems-on-chips. (iii) Development of energy-scavenging techniques for ultra-low power sensor network platforms.
(i) development of power modeling and estimation framework for systems-on-chip. (ii) Development of optimal allocation and scheduling techniques for energy-efficient mapping of multi-task applications onto multi-processor systems-on-chips. (iii) Development of energy-scavenging techniques for ultra-low power sensor network platforms. - Team leader: Petru Eles – Linköping University (Sweden)
development of optimization approaches for energy efficient, time constrained embedded systems; communication synthesis for energy-efficient real-time and fault-tolerant applications implemented on SoC; low power scheduling with voltage scaling and body biasing. - Team Leader: Jan Madsen - Technical University of Denmark (Denmark) (i) development of low-power asynchronous circuit design, in particular for efficient Network-on-Chip structures, (ii) development of multi-objective optimization approaches for exploring the mapping of multitask applications onto multiprocessor System-on-Chip, (iii) experience in design and modeling of wireless sensor network platforms.
- Team Leader: Lothar Thiele – ETH Zurich (Switzerland) (i) Combining scheduling methods with energy constraints, (ii) extensive experience in performance analysis for real-time embedded systems and interface-based approaches, (iii) experience in building and deploying sensor network platforms.
Affiliated Participants: Expertise and Roles
- Team Leader: Mircea R. Stan (Univ. of Virginia) (i) Power and thermal modeling at the device, circuit and system level. (ii) Self-consistent power modeling by taking into account thermal effects. (iii) Temperature-aware circuit design. Automotive computing applications.
- Team Leader: Roberto Zafalon – STMicroelectronics (Italy) (i) Provides an up-to-date view on industrial requirements for low-power system-on-chip platforms. (ii) Makes available to the activity’s participants up-to-date information on the power dissipated in current and up-coming advanced CMOS technologies, as developed by STMicroelectronics. (iii) Provides information on applications and architecture trends in the market of consume multimedia silicon platforms.
- Team Leader: Salvatore Carta – Università di Cagliari (Italy) (i) Cooperates with the cluster’s participant on the development of power analysis and modeling techniques for on-chip interconnects (networks-on-chip). (ii) Provides competences and reference flows for back-end design issues (power issues arising from low-level design – logic design, placement, routing, etc.)
(c) Artist Consortium, All Rights Reserved - 2006, 2007, 2008, 2009